Overview¶
- Numerical analysis in Python
- Tabular data
- Pandas object types
- Working with data frames in pandas
- Data input and output
Numerical analysis in Python¶
- As opposed to other programming languages (Julia, R, MatLab),
Python provides very bare bones functionality for numeric analysis.
- E.g. no built-in matrix/array object type, limited mathematical and statistical functions
In [1]:
# Representing 3x3 matrix with list
mat = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
In [2]:
# Subsetting 2nd row, 3rd element
mat[1][2]
Out[2]:
6
In [3]:
# Naturally, this representation
# breaks down rather quickly
mat * 2
Out[3]:
[[1, 2, 3], [4, 5, 6], [7, 8, 9], [1, 2, 3], [4, 5, 6], [7, 8, 9]]
NumPy - numerical analysis in Python¶
- NumPy (Numeric Python) package provides the basis of numerical computing in Python:
- multidimensional array
- mathematical functions for arrays
- array data I/O
- linear algebra, RNG, FFT, ...
In [4]:
# Using 'as' allows to avoid typing full name
# each time the module is referred to
import numpy as np
NumPy array¶
- Multidimensional (N) array object (aka ndarray) is a principal container for datasets in Python.
- It is the backbone of data frames, operating behind the scenes
In [5]:
arr = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
In [6]:
arr[1][2]
Out[6]:
6
In [7]:
arr * 2
Out[7]:
array([[ 2, 4, 6],
[ 8, 10, 12],
[14, 16, 18]])
Working with arrays¶
In [8]:
# Object type
type(arr)
Out[8]:
numpy.ndarray
In [9]:
# Array dimensionality
arr.ndim
Out[9]:
2
In [10]:
# Array size
arr.shape
Out[10]:
(3, 3)
In [11]:
# Calculating summary statistics on array
# axis indicates the dimension
# note that every list within a list
# is treated as a column (not row)
arr.mean(axis = 0)
Out[11]:
array([4., 5., 6.])
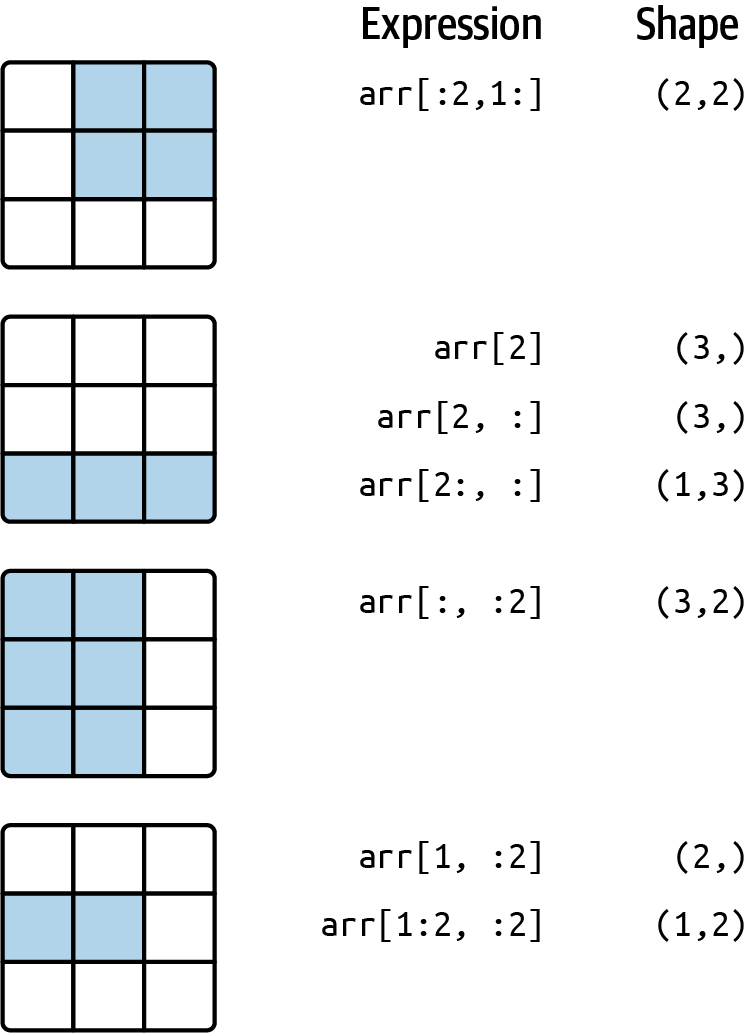
Tidy data¶
- Tidy data is a specific subset of rectangular data, where:
- Each variable is in a column
- Each observation is in a row
- Each value is in a cell

Source: R for Data Science

Pandas¶
- Standard Python library does not have data type for rectangular data
- However,
pandaslibrary has become the de facto standard for data manipulation pandasis built upon (and often used in conjuction with) other computational libraries- E.g.
numpy(array data type),scipy(linear algebra) andscikit-learn(machine learning)
In [12]:
import pandas as pd
Core pandas object types¶
- Series - one-dimensional sequence of values
- DataFrame - (typically) two-dimensional rectangular table
Series¶
- Series is a one-dimensional array-like object
In [13]:
sr1 = pd.Series([150.0, 120.0, 3000.0])
sr1
Out[13]:
0 150.0 1 120.0 2 3000.0 dtype: float64
In [14]:
sr1[0] # Slicing is similar to standard Python objects
Out[14]:
150.0
In [15]:
sr1[sr1 > 200] # But subsetting is also available
Out[15]:
2 3000.0 dtype: float64
Indexing in Series¶
- Another way to think about Series is as a ordered dictionary
In [16]:
d = {'apple': 150.0, 'banana': 120.0, 'watermelon': 3000.0}
In [17]:
sr2 = pd.Series(d)
sr2
Out[17]:
apple 150.0 banana 120.0 watermelon 3000.0 dtype: float64
In [18]:
sr2[0] # Recall that this slicing would be impossible for standard dictionary
Out[18]:
150.0
In [19]:
sr2.index # Sequence of labels is converted into an Index object
Out[19]:
Index(['apple', 'banana', 'watermelon'], dtype='object')
DataFrame - the workhorse of data analysis¶
- DataFrame is a rectangular table of data
In [20]:
# DataFrame can be constructed from
# a dict of equal-length lists/arrays
data = {'fruit': ['apple', 'banana', 'watermelon'],
'weight': [150.0, 120.0, 3000.0],
'berry': [False, True, True]}
df = pd.DataFrame(data)
df
Out[20]:
| fruit | weight | berry | |
|---|---|---|---|
| 0 | apple | 150.0 | False |
| 1 | banana | 120.0 | True |
| 2 | watermelon | 3000.0 | True |
Indexing in DataFrame¶
- DataFrame has both row and column indices
DataFrame.loc()provides method for label locationDataFrame.iloc()provides method for index location
In [21]:
df.iloc[0] # First row
Out[21]:
fruit apple weight 150.0 berry False Name: 0, dtype: object
In [22]:
df.iloc[:,0] # First column
Out[22]:
0 apple 1 banana 2 watermelon Name: fruit, dtype: object
Summary of indexing in DataFrame¶
| Expression | Selection Operation |
|---|---|
df[val] |
Column or sequence of columns +convenience (e.g. slice) |
df.loc[lab_i] |
Row or subset of rows by label |
df.loc[:, lab_j] |
Column or subset of columns by label |
df.loc[lab_i, lab_j] |
Both rows and columns by label |
df.iloc[i] |
Row or subset of rows by integer position |
df.iloc[:, j] |
Column or subset of columns by integer position |
df.iloc[i, j] |
Both rows and columns by integer position |
df.at[lab_i, lab_j] |
Single scalar value by row and column label |
df.iat[i, j] |
Single scalar value by row and column integer position |
Subsetting in DataFrame¶
In [23]:
df.iloc[:2] # Select the first two rows (with convenience shortcut for slicing)
Out[23]:
| fruit | weight | berry | |
|---|---|---|---|
| 0 | apple | 150.0 | False |
| 1 | banana | 120.0 | True |
In [24]:
df[:2] # Shortcut
Out[24]:
| fruit | weight | berry | |
|---|---|---|---|
| 0 | apple | 150.0 | False |
| 1 | banana | 120.0 | True |
In [25]:
df.loc[:, ['fruit', 'berry']] # Select the columns 'fruit' and 'berry'
Out[25]:
| fruit | berry | |
|---|---|---|
| 0 | apple | False |
| 1 | banana | True |
| 2 | watermelon | True |
In [26]:
df[['fruit', 'berry']] # Shortcut
Out[26]:
| fruit | berry | |
|---|---|---|
| 0 | apple | False |
| 1 | banana | True |
| 2 | watermelon | True |
Columns in DataFrame¶
In [27]:
df.columns # Retrieve the names of all columns (index object)
Out[27]:
Index(['fruit', 'weight', 'berry'], dtype='object')
In [28]:
df.columns[0] # This Index object is subsettable
Out[28]:
'fruit'
In [29]:
df.columns.str.startswith('fr') # As column names are strings, we can apply str methods
Out[29]:
array([ True, False, False])
In [30]:
df.iloc[:,df.columns.str.startswith('fr')] # This is helpful with more complicated column selection criteria
Out[30]:
| fruit | |
|---|---|
| 0 | apple |
| 1 | banana |
| 2 | watermelon |
Manipulating columns in DataFrame¶
In [31]:
df = df.rename(columns = {'weight': 'weight_g'}) # Columns can be renamed with dictionary mapping
In [32]:
df
Out[32]:
| fruit | weight_g | berry | |
|---|---|---|---|
| 0 | apple | 150.0 | False |
| 1 | banana | 120.0 | True |
| 2 | watermelon | 3000.0 | True |
In [33]:
df['weight_oz'] = 0 # Columns can be added or modified by assignment
In [34]:
df
Out[34]:
| fruit | weight_g | berry | weight_oz | |
|---|---|---|---|---|
| 0 | apple | 150.0 | False | 0 |
| 1 | banana | 120.0 | True | 0 |
| 2 | watermelon | 3000.0 | True | 0 |
In [35]:
df['weight_oz'] = df['weight_g'] * 0.04
In [36]:
df
Out[36]:
| fruit | weight_g | berry | weight_oz | |
|---|---|---|---|---|
| 0 | apple | 150.0 | False | 6.0 |
| 1 | banana | 120.0 | True | 4.8 |
| 2 | watermelon | 3000.0 | True | 120.0 |
Filtering in DataFrame¶
In [37]:
df[df.loc[:,'berry'] == False] # Select rows where fruits are not berries
Out[37]:
| fruit | weight_g | berry | weight_oz | |
|---|---|---|---|---|
| 0 | apple | 150.0 | False | 6.0 |
In [38]:
df[df['berry'] == False] # The same can be achieved with more concise syntax
Out[38]:
| fruit | weight_g | berry | weight_oz | |
|---|---|---|---|---|
| 0 | apple | 150.0 | False | 6.0 |
In [39]:
weight200 = df[df['weight_g'] > 200] # Create new dataset with rows where weight is higher than 200 grams
weight200
Out[39]:
| fruit | weight_g | berry | weight_oz | |
|---|---|---|---|---|
| 2 | watermelon | 3000.0 | True | 120.0 |
Variable transformation¶
- Lambda functions can be used to transform data with
map()method
In [40]:
df['fruit'].map(lambda x: x.upper())
Out[40]:
0 APPLE 1 BANANA 2 WATERMELON Name: fruit, dtype: object
In [41]:
transform = lambda x: x.capitalize()
In [42]:
transformed = df['fruit'].map(transform)
In [43]:
transformed
Out[43]:
0 Apple 1 Banana 2 Watermelon Name: fruit, dtype: object
File object¶
- File object in Python provides the main interface to external files
- In contrast to other core types, file objects are created not with a literal,
- But with a function,
open():
<variable_name> = open(<filepath>, <mode>)
Data input and output¶
- Modes of file objects allow to:
- (
r)ead a file (default) - (
w)rite an object to a file - e(
x)clusively create, failing if a file exists - (
a)ppend to a file
- (
- You can
r+mode if you need to read and write to file
Data output example¶
In [44]:
# Create a new file object in write mode
f = open('../temp/test.txt', 'w')
In [45]:
# Write a string of characters to it
f.write('This is a test file.')
Out[45]:
20
In [46]:
# Flush output buffers to disk and close the connection
f.close()
Data input example¶
- To avoid keeping track of open file connections,
withstatement can be used
In [47]:
# Note that we use 'r' mode for reading
with open('../temp/test.txt', 'r') as f:
text = f.read()
In [48]:
text
Out[48]:
'This is a test file.'
Reading and writing data in pandas¶
pandasprovides high-level methods that takes care of file connections- These methods all follow the same
read_<format>andto_<format>name patterns - CSV (comma-separated value) files are the standard of interoperability
<variable_name> = pd.read_<format>(<filepath>)
<variable_name>.to_<format>(<filepath>)
Reading data in pandas example¶
- We will use the data from Kaggle 2022 Machine Learning and Data Science Survey
- For more information you can read the executive summary
In [49]:
# We specify that we want to combine first two rows as a header
kaggle2022 = pd.read_csv(
'../data/kaggle_survey_2022_responses.csv',
header = [0,1]
)
/tmp/ipykernel_776815/2279990677.py:2: DtypeWarning: Columns (208,225,255,257,260,270,271,277) have mixed types. Specify dtype option on import or set low_memory=False. kaggle2022 = pd.read_csv(
Visual data inspection¶
In [50]:
kaggle2022.head() # Returns the top n (n=5 default) rows
Out[50]:
| Duration (in seconds) | Q2 | Q3 | Q4 | Q5 | Q6_1 | Q6_2 | Q6_3 | Q6_4 | Q6_5 | ... | Q44_3 | Q44_4 | Q44_5 | Q44_6 | Q44_7 | Q44_8 | Q44_9 | Q44_10 | Q44_11 | Q44_12 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Duration (in seconds) | What is your age (# years)? | What is your gender? - Selected Choice | In which country do you currently reside? | Are you currently a student? (high school, university, or graduate) | On which platforms have you begun or completed data science courses? (Select all that apply) - Selected Choice - Coursera | On which platforms have you begun or completed data science courses? (Select all that apply) - Selected Choice - edX | On which platforms have you begun or completed data science courses? (Select all that apply) - Selected Choice - Kaggle Learn Courses | On which platforms have you begun or completed data science courses? (Select all that apply) - Selected Choice - DataCamp | On which platforms have you begun or completed data science courses? (Select all that apply) - Selected Choice - Fast.ai | ... | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Reddit (r/machinelearning, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Kaggle (notebooks, forums, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Course Forums (forums.fast.ai, Coursera forums, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - YouTube (Kaggle YouTube, Cloud AI Adventures, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Podcasts (Chai Time Data Science, O’Reilly Data Show, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Blogs (Towards Data Science, Analytics Vidhya, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Journal Publications (peer-reviewed journals, conference proceedings, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Slack Communities (ods.ai, kagglenoobs, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - None | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Other | |
| 0 | 121 | 30-34 | Man | India | No | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 462 | 30-34 | Man | Algeria | No | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 293 | 18-21 | Man | Egypt | Yes | Coursera | edX | NaN | DataCamp | NaN | ... | NaN | Kaggle (notebooks, forums, etc) | NaN | YouTube (Kaggle YouTube, Cloud AI Adventures, ... | Podcasts (Chai Time Data Science, O’Reilly Dat... | NaN | NaN | NaN | NaN | NaN |
| 3 | 851 | 55-59 | Man | France | No | Coursera | NaN | Kaggle Learn Courses | NaN | NaN | ... | NaN | Kaggle (notebooks, forums, etc) | Course Forums (forums.fast.ai, Coursera forums... | NaN | NaN | Blogs (Towards Data Science, Analytics Vidhya,... | NaN | NaN | NaN | NaN |
| 4 | 232 | 45-49 | Man | India | Yes | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | Blogs (Towards Data Science, Analytics Vidhya,... | NaN | NaN | NaN | NaN |
5 rows × 296 columns
Visual data inspection continued¶
In [51]:
kaggle2022.tail() # Returns the bottom n (n=5 default) rows
Out[51]:
| Duration (in seconds) | Q2 | Q3 | Q4 | Q5 | Q6_1 | Q6_2 | Q6_3 | Q6_4 | Q6_5 | ... | Q44_3 | Q44_4 | Q44_5 | Q44_6 | Q44_7 | Q44_8 | Q44_9 | Q44_10 | Q44_11 | Q44_12 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Duration (in seconds) | What is your age (# years)? | What is your gender? - Selected Choice | In which country do you currently reside? | Are you currently a student? (high school, university, or graduate) | On which platforms have you begun or completed data science courses? (Select all that apply) - Selected Choice - Coursera | On which platforms have you begun or completed data science courses? (Select all that apply) - Selected Choice - edX | On which platforms have you begun or completed data science courses? (Select all that apply) - Selected Choice - Kaggle Learn Courses | On which platforms have you begun or completed data science courses? (Select all that apply) - Selected Choice - DataCamp | On which platforms have you begun or completed data science courses? (Select all that apply) - Selected Choice - Fast.ai | ... | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Reddit (r/machinelearning, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Kaggle (notebooks, forums, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Course Forums (forums.fast.ai, Coursera forums, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - YouTube (Kaggle YouTube, Cloud AI Adventures, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Podcasts (Chai Time Data Science, O’Reilly Data Show, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Blogs (Towards Data Science, Analytics Vidhya, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Journal Publications (peer-reviewed journals, conference proceedings, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Slack Communities (ods.ai, kagglenoobs, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - None | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Other | |
| 23992 | 331 | 22-24 | Man | United States of America | Yes | NaN | NaN | NaN | NaN | NaN | ... | NaN | Kaggle (notebooks, forums, etc) | NaN | YouTube (Kaggle YouTube, Cloud AI Adventures, ... | Podcasts (Chai Time Data Science, O’Reilly Dat... | NaN | Journal Publications (peer-reviewed journals, ... | NaN | NaN | NaN |
| 23993 | 330 | 60-69 | Man | United States of America | Yes | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | YouTube (Kaggle YouTube, Cloud AI Adventures, ... | NaN | NaN | NaN | NaN | NaN | NaN |
| 23994 | 860 | 25-29 | Man | Turkey | No | NaN | NaN | NaN | DataCamp | NaN | ... | NaN | Kaggle (notebooks, forums, etc) | NaN | YouTube (Kaggle YouTube, Cloud AI Adventures, ... | NaN | NaN | NaN | NaN | NaN | NaN |
| 23995 | 597 | 35-39 | Woman | Israel | No | NaN | NaN | Kaggle Learn Courses | NaN | NaN | ... | NaN | NaN | NaN | YouTube (Kaggle YouTube, Cloud AI Adventures, ... | NaN | NaN | NaN | NaN | NaN | NaN |
| 23996 | 303 | 18-21 | Man | India | Yes | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | Other |
5 rows × 296 columns
Writing data out in Python¶
- Note that when writing data out we start with the object name storing the dataset
- I.e.
df.to_csv(path)as opposed todf = pd.read_csv(path) - Pandas can also write out into other data formats
- E.g.
df.to_excel(path),df.to_stata(path)
In [52]:
kaggle2022.to_csv('../temp/kaggle2022.csv')
Summarizing numeric variables¶
- DataFrame methods in pandas can automatically handle (exclude) missing data (
NaN)
In [53]:
kaggle2022.describe() # DataFrame.describe() provides an range of summary statistics
Out[53]:
| Duration (in seconds) | |
|---|---|
| Duration (in seconds) | |
| count | 2.399700e+04 |
| mean | 1.009010e+04 |
| std | 1.115403e+05 |
| min | 1.200000e+02 |
| 25% | 2.640000e+02 |
| 50% | 4.140000e+02 |
| 75% | 7.150000e+02 |
| max | 2.533678e+06 |
Methods for summarizing numeric variables¶
In [54]:
kaggle2022.iloc[:,0].mean() # Rather than using describe(), we can apply individual methods
Out[54]:
10090.095845313997
In [55]:
kaggle2022.iloc[:,0].median() # Median
Out[55]:
414.0
In [56]:
kaggle2022.iloc[:,0].std() # Standard deviation
Out[56]:
111540.30746801202
In [57]:
import statistics ## We don't have to rely only on methods provided by `pandas`
statistics.stdev(kaggle2022.iloc[:,0])
Out[57]:
111540.30746801202
Summarizing categorical variables¶
In [58]:
kaggle2022.describe(include = 'all') # Adding include = 'all' tells pandas to summarize all variables
Out[58]:
| Duration (in seconds) | Q2 | Q3 | Q4 | Q5 | Q6_1 | Q6_2 | Q6_3 | Q6_4 | Q6_5 | ... | Q44_3 | Q44_4 | Q44_5 | Q44_6 | Q44_7 | Q44_8 | Q44_9 | Q44_10 | Q44_11 | Q44_12 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Duration (in seconds) | What is your age (# years)? | What is your gender? - Selected Choice | In which country do you currently reside? | Are you currently a student? (high school, university, or graduate) | On which platforms have you begun or completed data science courses? (Select all that apply) - Selected Choice - Coursera | On which platforms have you begun or completed data science courses? (Select all that apply) - Selected Choice - edX | On which platforms have you begun or completed data science courses? (Select all that apply) - Selected Choice - Kaggle Learn Courses | On which platforms have you begun or completed data science courses? (Select all that apply) - Selected Choice - DataCamp | On which platforms have you begun or completed data science courses? (Select all that apply) - Selected Choice - Fast.ai | ... | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Reddit (r/machinelearning, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Kaggle (notebooks, forums, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Course Forums (forums.fast.ai, Coursera forums, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - YouTube (Kaggle YouTube, Cloud AI Adventures, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Podcasts (Chai Time Data Science, O’Reilly Data Show, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Blogs (Towards Data Science, Analytics Vidhya, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Journal Publications (peer-reviewed journals, conference proceedings, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Slack Communities (ods.ai, kagglenoobs, etc) | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - None | Who/what are your favorite media sources that report on data science topics? (Select all that apply) - Selected Choice - Other | |
| count | 2.399700e+04 | 23997 | 23997 | 23997 | 23997 | 9699 | 2474 | 6628 | 3718 | 944 | ... | 2678 | 11181 | 4006 | 11957 | 2120 | 7766 | 3804 | 1726 | 1268 | 835 |
| unique | NaN | 11 | 5 | 58 | 2 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| top | NaN | 18-21 | Man | India | No | Coursera | edX | Kaggle Learn Courses | DataCamp | Fast.ai | ... | Reddit (r/machinelearning, etc) | Kaggle (notebooks, forums, etc) | Course Forums (forums.fast.ai, Coursera forums... | YouTube (Kaggle YouTube, Cloud AI Adventures, ... | Podcasts (Chai Time Data Science, O’Reilly Dat... | Blogs (Towards Data Science, Analytics Vidhya,... | Journal Publications (peer-reviewed journals, ... | Slack Communities (ods.ai, kagglenoobs, etc) | None | Other |
| freq | NaN | 4559 | 18266 | 8792 | 12036 | 9699 | 2474 | 6628 | 3718 | 944 | ... | 2678 | 11181 | 4006 | 11957 | 2120 | 7766 | 3804 | 1726 | 1268 | 835 |
| mean | 1.009010e+04 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| std | 1.115403e+05 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| min | 1.200000e+02 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 25% | 2.640000e+02 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 50% | 4.140000e+02 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 75% | 7.150000e+02 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| max | 2.533678e+06 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
11 rows × 296 columns
Methods for summarizing categorical variables¶
In [59]:
kaggle2022.iloc[:,2].mode() # Mode, most frequent value
Out[59]:
0 Man Name: (Q3, What is your gender? - Selected Choice), dtype: object
In [60]:
kaggle2022.iloc[:,2].value_counts() # Counts of unique values
Out[60]:
Man 18266 Woman 5286 Prefer not to say 334 Nonbinary 78 Prefer to self-describe 33 Name: (Q3, What is your gender? - Selected Choice), dtype: int64
In [61]:
kaggle2022.iloc[:,2].value_counts(normalize = True) # We can further normalize them by the number of rows
Out[61]:
Man 0.761178 Woman 0.220278 Prefer not to say 0.013918 Nonbinary 0.003250 Prefer to self-describe 0.001375 Name: (Q3, What is your gender? - Selected Choice), dtype: float64
Summary of descriptive statistics methods¶
| Method | Numeric | Categorical | Description |
|---|---|---|---|
count |
yes | yes | Number of non-NA observations |
value_counts |
yes | yes | Number of unique observations by value |
describe |
yes | yes | Set of summary statistics for Series/DataFrame |
min, max |
yes | yes (caution) | Minimum and maximum values |
quantile |
yes | no | Sample quantile ranging from 0 to 1 |
sum |
yes | yes (caution) | Sum of values |
prod |
yes | no | Product of values |
mean |
yes | no | Mean |
median |
yes | no | Median (50% quantile) |
var |
yes | no | Sample variance |
std |
yes | no | Sample standard deviation |
skew |
yes | no | Sample skewness (third moment) |
kurt |
yes | no | Sample kurtosis (fourth moment) |
Next Week¶
- Data Analysis and Communicating Results